In the rapidly evolving field of artificial intelligence, the challenge of optimizing large language models (LLMs) for specific applications is a pressing concern. Two prominent methodologies, fine-tuning and in-context learning (ICL), are at the forefront of this optimization. Fine-tuning involves adjusting a pre-trained model on a specific dataset to tailor its performance. In contrast, ICL leverages the model’s internal capabilities without altering its parameters, instead guiding it with contextual examples embedded within the prompt. While both approaches aim to enhance a model’s ability to tackle downstream tasks, recent insights indicate that ICL generally exhibits superior generalization capabilities, albeit at a cost to computational efficiency during inference.
The Quest for Generalization: A Comparative Study
A recent study conducted by researchers at Google DeepMind and Stanford University delves into the generalization capabilities of fine-tuning versus ICL. The researchers meticulously designed controlled synthetic datasets with complex structures, featuring imaginary relationships and conceptual hierarchies to assess how well models adapt to new tasks. This innovative methodology involved substituting recognizable terms with nonsensical counterparts to ensure that model training was based purely on the structure rather than pre-existing knowledge.
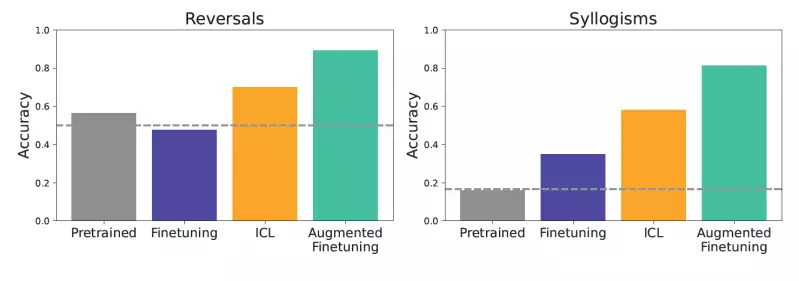
Their findings presented a compelling argument: while fine-tuning enables models to learn from specialized datasets, ICL often outperformed it in terms of adaptability and reasoning tasks. For instance, when tasked with logical deductions or relational inversions, models employing ICL displayed a higher accuracy rate compared to those solely relying on fine-tuning methods. Such insights underscore the necessity for developers to weigh the computational trade-offs when selecting an approach for specific LLM applications.
The Impact of Computational Efficiency
One of the critical considerations for practitioners in this domain is the trade-off between computational expense and model performance. Fine-tuning traditionally requires less computational overhead during inference as it prepares the model for specific queries through targeted training. However, it is worth noting that ICL’s flexibility comes at an increased computational cost per query due to the need for larger context inputs. This is a significant factor when deploying models in real-world applications where repetitive querying occurs.
Andrew Lampinen, a research scientist at Google DeepMind, pointed out that while ICL presents a more flexible learning architecture, it also necessitates a robust computational foundation to ensure feasibility across applications. Thus, understanding the balance between these methodologies is crucial for enterprises aiming to utilize LLMs effectively without overshooting their resource allocations.
Augmented Fine-Tuning: A Novel Solution
Building on the strengths of ICL, the researchers proposed an innovative approach: augmented fine-tuning. This method capitalizes on ICL’s generalization prowess by incorporating its capabilities into the fine-tuning phase. The essence of this strategy lies in enhancing the training dataset with various in-context inferences generated by the LLM itself. This creates a richer dataset that aids the model in understanding complex relationships within the data.
The researchers identified two strategies for data augmentation. The local strategy emphasizes individual pieces of information, where the LLM is prompted to reformulate sentences to create variations. The global strategy, on the other hand, involves presenting the entire training dataset as context, prompting the model to generate connections among different pieces of information. These methods not only boost the dataset’s diversity but also enhance the model’s reasoning capabilities.
Results from experiments indicated that models utilizing augmented fine-tuning significantly outperformed both standard fine-tuning and ICL approaches. For example, if a company document stated that “XYZ is an internal tool for analyzing data,” models trained with augmented fine-tuning were better equipped to respond to related queries like, “What internal tools for data analysis exist?”
A Strategic Investment for Enterprises
This augmented fine-tuning methodology opens new avenues for enterprises aiming to unlock the potential of LLM applications. By investing in the creation of ICL-augmented datasets, organizations can craft fine-tuned models that offer enhanced generalization without continuous, high computational costs. Lampinen cautioned, however, that while augmented fine-tuning may require an upfront investment in terms of time and resources, it is ultimately less expensive when amortized over the model’s lifetime use.
The assumption is that this approach will render LLM applications not just more robust but also more adaptable to diverse, real-world inputs. Businesses seeking optimized performance must carefully evaluate the implications of such strategies, especially in contexts where the traditional fine-tuning process does not yield satisfactory results.
Ultimately, as research continues to unfold and refine our understanding of LLM generalization and adaptation, the innovative strategies formulated by Lampinen and his team pave the way for more effective applications of artificial intelligence, promising improved outcomes in a variety of domains and business contexts.